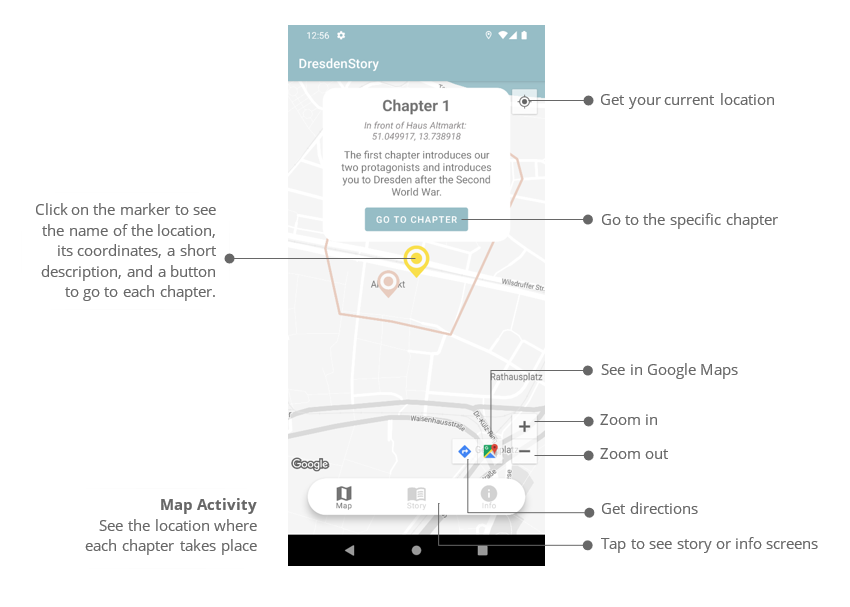
An implementation of [one step of] the beta-reduction from the lambda calculus. This sed-script
can be considered to be an implementation of a simple but computationally universal (i.e.
Turing-complete) functional programming language.
The input language imitates the standard lambda-calculus notation but replaces the Greek lambda
with easy-to-type symbol \ (backslash) and omits a dots in lambda definitions. E.g. the
identity function in such a modified notation can be defined as \x x.
A custom definitions (e.g., true = \x\y x) and comments (any text after -- and upto the end
of the same line is ignored) are supported only via the additional sed-script
preprocessor.sed.
There is also a support for the de Bruijn indices, which can be [optionally] placed in angle
brackets after an identifiers (see below for a little bit more details).
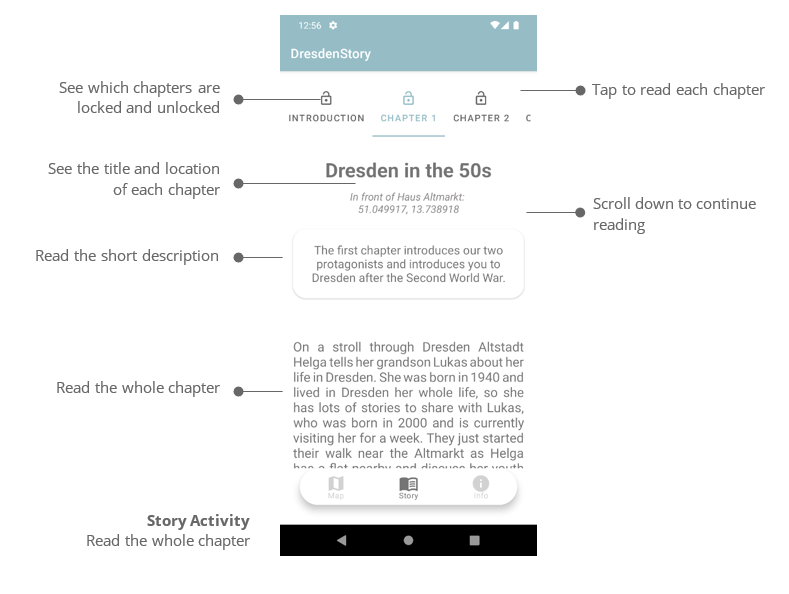
Although it performs only single beta-reduction, in theory you can call this script repeatedly
until it approaches a fixed point (or even modify the script so that it will loop until the
stabilization). See, for example, the shell-script eval.sh and try something like
echo "(\w\x x w) y" | ./eval.sh -.
N.B., this work focuses on the pure untyped lambda calculus with the “call by name” reduction
strategy (in fact, the script uses a more straightforward strategy — namely “call by
macro expansion” in which we perform direct textual substitution).
The call by name reduction chooses the leftmost, outermost redex, but never reduces inside
abstractions.
E.g., id(id(\z id z)) -> id (\z id z) -> \z id z, where id = \x x.
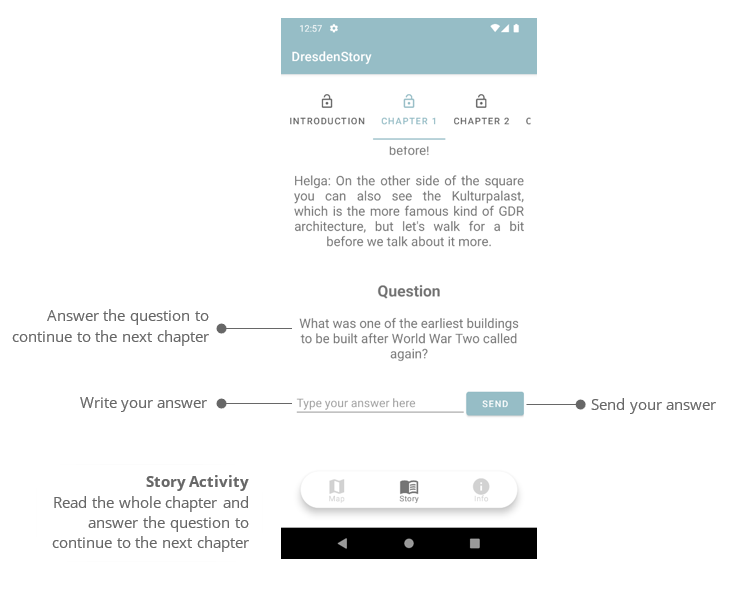
In “call by name” the expressions are always passed as parameters without any attempt to
reduce them; the reduction takes place later, if neccessary.
In “lazy evaluation” (a variant of “call by need” strategy), we need to track repetitions of a
parameter (enveloping it in a so called “thunk”); when we reduce one we track all others. This
allows each parameter to be computed only once at maximum (or even never at all). The lazy
evaluation arrives at its conclusion with the fewest reductions. So, it would be nice to
implement the lazy evaluation but currently this script uses the “call by name” stratedy as more
simple one to implement (for how to store a thunks across the script invocations?).
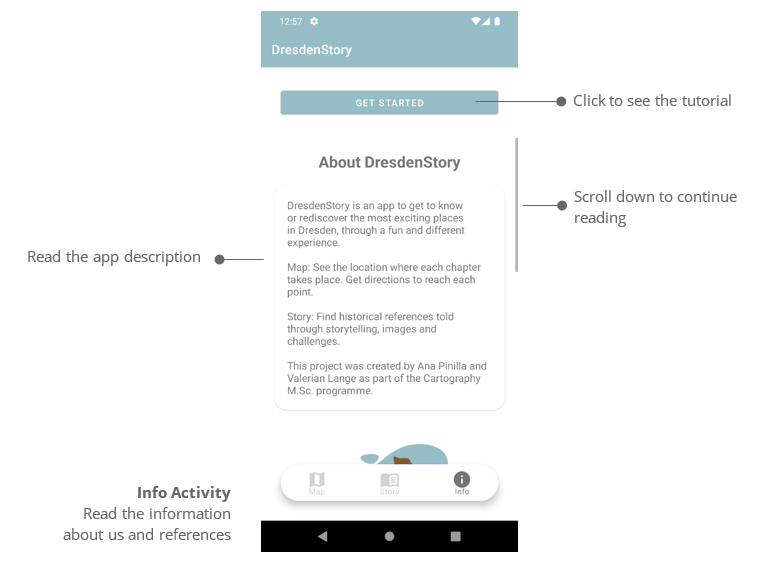
Additionally, the script supports a de Bruijn indices (one-based unary numbers in an optional
angle brackets after an identifier). In de Bruijn notation, a variable occurence is represented
by the number of lambdas between this occurrence and the lambda binding the variable. E.g.,
\x.x (\y.y x) is written in de Bruijn’s notation as \0 (\0 1). Note, that this script uses
one-based indices, i.e., the last example must can be translated into the input language of
this interpreter as \ <1> (\ <1> <11>)). In this sed-script the de Bruijn notation is vital
because of its capture-avoiding properties.
There is no any IO — a source program itself is the input and its transformed version is the
output.
The script read a source program from the standard input. So, you can use the script this way:
echo '(\x x) y' | ./beta-reducer.sed
If you place a comma symbol right at the end of input then the script will act as an
“echo”-command, printing its input expression “prettified”, that is annotated with de Bruijn
indices and with unneeded parenthesis removed. E.g.:
echo '(\x x) y,' | ./beta-reducer.sed`
To process a macro-definitions and remove comments it’s possible to filter an extended
lambda-script with such a features through the sed-script preprocessor.sed like this:
cat some-extended-script.lambda | ./preprocessor.sed | ./beta-reducer.sed
Beware that it’s a quite inefficient to run a lambda-programs this way — at each step it
performs a complete reparsing of a given expression instead of manipulating an abstract syntax
tree created only once.
Learn more at http://en.wikipedia.org/wiki/lambda_calculus
In near future I will write an extended explanation of this script in my blog, stay tuned. 🙂
(C) Written by Circiter (mailto:xcirciter@gmail.com).
Repository: https://github.com/Circiter/beta-reducer-in-sed
License: MIT.

https://github.com/Circiter/beta-reducer-in-sed